论文信息
论文下载:Keyword-Enhanced Multi-Expert Framework for Hate Speech Detection
标题:关键词增强的多专家框架用于仇恨言论检测
作者:钟玮瑜、吴乔峰(共一)、卢国钧、薛云、胡晓辉(通讯)
发表地点:Mathematics 2022, 10(24), 4706
摘要
由于仇恨言论在互联网上的传播,会给人的身心健康和社会带来极大的危害,因此建立和促进仇恨言论检测的发展并采取一定的回避机制变得非常迫切。目前现有的仇恨言论检测方法,容易忽略目标句子的情感特征,难以识别出一些隐式的仇恨言论。然而,从其他情感资源中获取更多的情感信息将显著影响仇恨言论检测的性能。在利用外部情感信息时,也不能忽略句子本身的关键信息。于是本文提出了一个基于句子本身关键信息和外部情感信息的仇恨言论检测框架。最后在三个公共数据集上的实验结果证明了我们模型的有效性。
介绍
随着社交媒体和移动互联网平台的广泛使用,网络言论的传播速度和发布自由度不断提高,导致仇恨言论恶意泛滥。接触此类语言可能会对受害者的心理健康造成负面影响,从而引发严重的社会问题。为了防止进一步的负面影响,当局需要介入检测网络仇恨言论。因此,快速准确地自动检测仇恨言论已成为自然语言处理领域的热门研究课题。近年来,仇恨言论检测备受关注。

图 1 显示了一个例子,其中第一句包含仇恨词汇 “他妈的援助”(fucking aids),这是一种明显的攻击性仇恨言论,而第二句没有明显的仇恨词汇或语义,是一个积极的句子。
利用深度学习检测仇恨言论的方法是近年来大多数研究的重点。然而,以往的研究忽略了目标检测句子的情感特征,仅使用预训练模型或深度神经网络来获取语义特征。Wang, C. [6]的研究表明,仇恨言论的语义具有强烈的负面情绪倾向。为了克服这一问题,最近的研究提出使用多任务学习(MTL),通过使用情感信息来提高仇恨言论检测的性能[7]。迁移学习是从训练数据中获得的可通用知识迁移到目标任务的过程。MTL 是迁移学习的一种,它包括同时学习多个相关任务,让这些任务在学习过程中共享信息,并利用不同任务之间的相关性来提高模型在每个任务上的性能和泛化能力。Kapil, P. [8]提出了一种深度 MTL 框架,利用多个相关分类任务中的有用信息来进行仇恨言论检测;该框架采用了一种硬参数共享方法,容易产生负迁移。Zhou, X. [9]使用多个特征提取单元共享多任务参数,从而使模型能够进行情感知识共享。然后,使用门控网络来融合仇恨言论检测的特征。该模型采用了软参数共享方法,将一个专家分成多个专家,从而缓解了硬参数带来的负迁移问题。
虽然近年来仇恨言论检测取得了不错的成绩,但仍存在以下问题:(1)仇恨言论检测中最新使用的多任务框架是软参数共享[9],即所有专家共享所有任务,但仇恨言论检测和情感分析任务既有正相关关系,也有负相关关系。正相关是指有利于主要任务拟合的参数关系,反之,负相关则不利。如果不分离任务间的负相关参数,作为任务的一部分就会出现一些噪音,从而导致负迁移。此外,在使用多个专家时,由于专家们拥有来自不同任务的丰富信息,简单的门控网络无法有效融合和过滤不同的信息。(2) 目前的工作缺乏从句子中提取关键信息(如关键词)的能力[5]。它不能有效识别不同类型的仇恨词,如亵渎词,也不能识别某些身份词与冒犯性语句之间的关联。某些身份词(尤其是涉及少数群体的身份词)主要出现在具有攻击性的文本中[10],如句子 “这也是奥巴马的许多政策被推翻/废除的原因,只是因为黑人做了这些事。”中没有明显的仇恨词,而是通过身份词 “黑人 “进行种族歧视。
为解决上述问题,我们提出了以下方法。(1) 对于第一个问题,我们受到最近的渐进分层提取(PLE)模型[11]和门控网络研究[12]的启发。我们将特征提取单元(如专家模块)分为共享部分和特定任务部分。这种方法强化了任务本身的独立特征,更好地减少了弱相关任务共享参数造成的负迁移。此外,我们还设计了一个特征过滤门,可以更好地融合和过滤多个专家模块的信息。(2) 为了解决第二个问题,我们从最近的对比学习模型[13]中得到启发,提出了一个解决方案。我们的模型将对比学习应用于英语仇恨言论检测,使用脏话词典和身份术语词典来构建正反实例。这一结果使模型对关键词语更加敏感,从而可以学习各类仇恨词语或身份术语词语与攻击性语句之间的关联。总之,我们的研究有以下贡献:
- 为了更好地研究仇恨信息和情感信息之间的相互作用,我们提出了一种更适合仇恨言论检测的 MTL 模型,该模型使用共享专家和特定任务专家来提取特征,最后使用特征过滤门来融合特征。
- 鉴于之前的工作中缺乏对重要词语信息的使用,我们在预训练模型中引入了对比学习,使我们的模型能够更好地识别文本中的关键词。
- 在三个基准数据集上的实验结果表明,我们的模型在仇恨言论检测方面非常有效。
方法
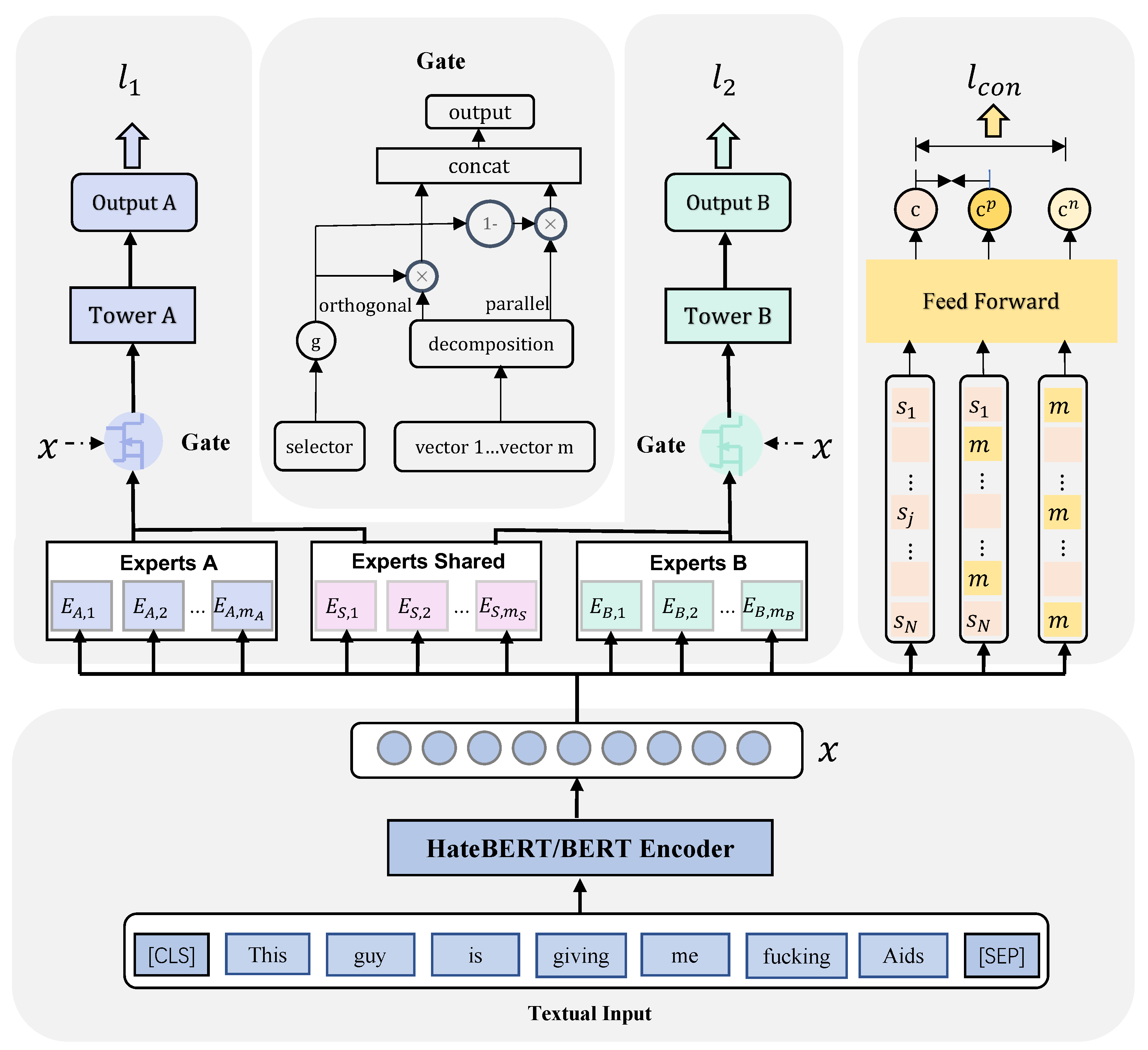
本节将介绍我们的仇恨言论检测关键字增强多专家框架模型(KMT)。该模型利用句子的关键信息和外部情感信息来改进仇恨言论检测。
KMT 的总体架构如图 2 所示。该框架由四个模块组成:(1)文本输入模块。图中底部显示的是文本输入模块,该模块使用预训练模型 BERT 或 HateBERT 对输入句子进行编码,并生成上下文和语义整合的输入向量 x;(2)多任务学习模块。图中左上方为多任务学习模块,我们利用多任务学习框架将情感信息和仇恨信息进行交互,学习共享特征和特定任务特征,利用情感信息辅助仇恨言论检测;(3)特征过滤模块。图中门为特征过滤模块,用于对专家模块输出的特征进行过滤和融合,筛选出重要的情感信息和仇恨言论信息;(4)对比学习模块。图中右上方为对比学习模块,用于提取句子中的关键信息,提高模型对句子关键词的敏感度。最后,对 MTL 模块和对比学习模块进行联合训练。

