论文信息
论文下载:Neighbor Contrastive Learning on Learnable Graph Augmentation
标题:基于可学习图增强的邻居监督图对比学习
作者:Xiao Shen(海南大学), Dewang Sun, Shirui Pan, Xi Zhou, Laurence T. Yang
发表地点:AAAI 2023
代码开源:https://github.com/shenxiaocam/NCLA
摘要
近年来,旨在从未标记的图中学习表示的图对比学习(GCL)取得了长足的进步。然而,现有的GCL方法大多采用人工设计的图增强,对各种图数据集都很敏感。此外,最初在计算机视觉中产生的对比损失已直接应用于图形数据,其中相邻节点被视为负值,因此与锚点相距很远。然而,这与网络的同质假设相矛盾,即连接的节点通常属于同一类,并且应该彼此靠近。在这项工作中,我们提出了一种名为NCLA的端到端自动GCL方法,用于将邻居对比学习应用于可学习图增强。多头图注意力机制自动学习多个自适应拓扑图增强视图,无需先验领域知识即可兼容各种图数据集。此外,通过将网络拓扑作为监督信号,设计了邻域对比损失,以允许每个锚点具有多个正信号。在拟议的 NCLA 中,增强和嵌入都是端到端学习的。在基准数据集上的大量实验表明,当标签极其有限时,NCLA在自监督GCL上产生了最先进的节点分类性能,甚至超过了监督节点。我们的代码在 https://github.com/shenxiaocam/NCLA 上发布。
介绍
在过去几年中,图神经网络(GNN)因其在节点分类(Kipf 和 Welling,2017 年)、链接预测(Shen 和 Chung,2020 年)和图分类等各种图挖掘任务中的出色表现而备受关注(Hamilton, Ying 和 Leskovec 2017)。现有的大多数 GNN 都是以监督的方式进行训练的,这在很大程度上依赖于大量注释良好的标签。然而,在现实世界的应用中,收集大量带标签的图结构数据往往需要耗费大量资源和时间(Shen 等人,2020a;Shen 等人,2020b;Shen、Mao 和 Chung,2020;Wu 等人,2020;Dai 等人,2022)。
对比学习(Contrastive Learning,CL)是最具代表性的自监督学习技术之一,可以减少对人工标签的依赖。对比学习在计算机视觉(CV)(Zhu 等人,2020 年)和自然语言处理(NLP)(Aberdam 等人,2021 年)的无监督表示学习中表现出了前所未有的性能。最近,在图对比学习(GCL)(Hassani 和 Khasahmadi,2020 年;Zhu 等人,2020 年;Xia 等人,2022a;Xia 等人,2022b;Zheng 等人,2022 年)的发展启发下,人们投入了巨大的努力,将 GNN 与 CL 结合起来,从无标签图中学习稳健的表示。
现有的 GCL 方法大多采用类似的模式。首先,它们采用各种图增强策略,如节点丢弃(You 等人,2020 年)、边扰动(Zhu 等人,2020 年)、属性掩蔽(Zhu 等人,2021 年)、子图(Yang 等人,2022 年)和图扩散(Hassani 和 Khasahmadi,2020 年),生成多个具有差异的图增强视图。其次,他们应用了 CV 中广泛使用的对比损失,如 InfoNCE(Van den Oord、Li 和 Vinyals,2018 年)、归一化温度标度交叉熵(NT-Xent)(Zhu et al. 2020)、Jensen-Shannon Divergence(JSD)(Nowozin、Cseke 和 Tomioka,2016)和 Triplet loss(Schroff、Kalenichenko 和 Philbin,2015)等,根据 InfoMax(Linsker,1988)原理提取不同增强视图之间的共同核心信息。尽管 GCL 得到了蓬勃发展,但标准范式在图增强和对比目标方面仍存在一些缺陷。
CL的理论和实证分析表明,好的增强视图应该是多样化的,同时保持与任务相关的信息完好无损(Tian等人,2020)。然而,现有的手工图增强策略会随机扰动图拓扑结构,无法保持任务相关信息的完整性。例如,丢弃一条重要的边会严重破坏与下游任务高度相关的图拓扑结构,从而导致图嵌入质量低下(Zhu 等,2021)。此外,由于图数据的多样性,目前还没有适用于不同数据集的通用图增强技术(You 等人,2020 年;You 等人,2021 年)。因此,现有的临时图增强方法必须根据先前的领域知识或反复试验为每个图数据集手动选择(You 等人,2020 年),这大大限制了现有 GCL 方法的效率和普遍适用性。
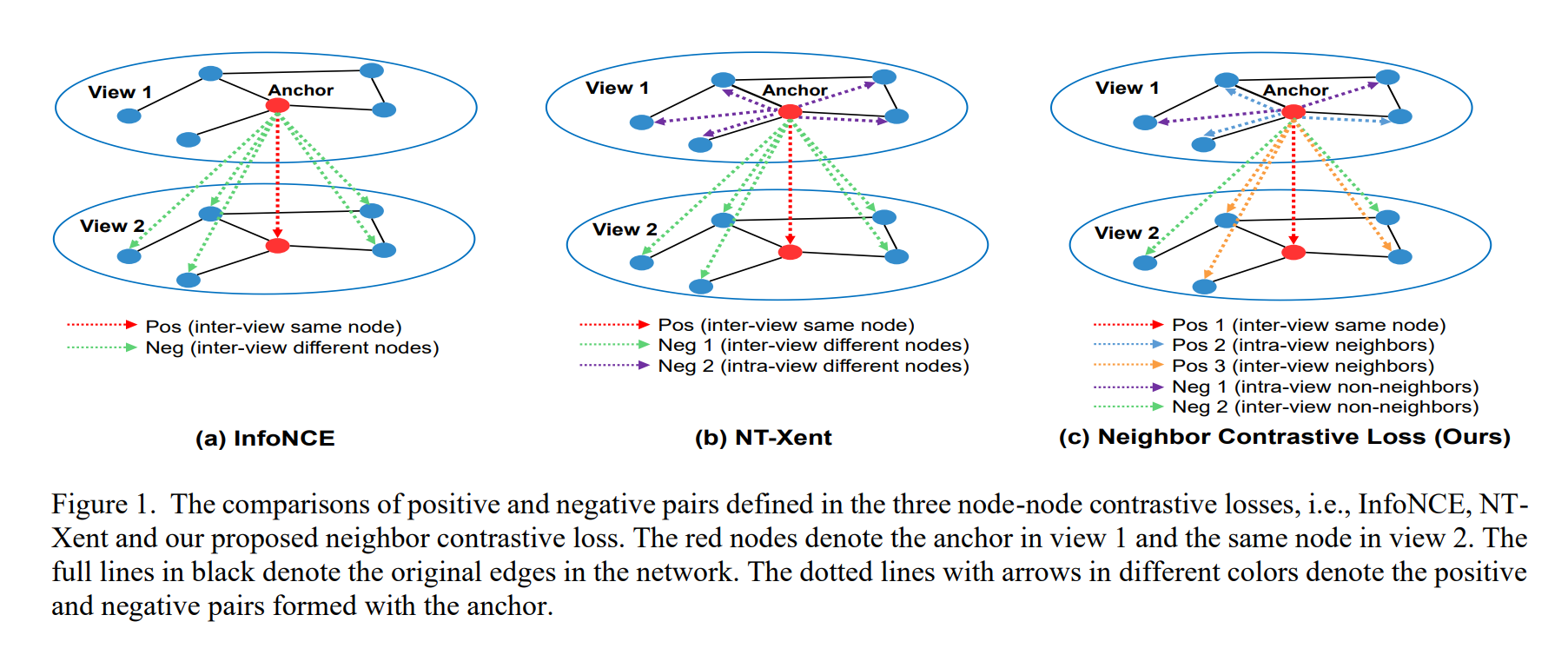
另一方面,现有的 GCL 方法直接将最初在 CV 中提出的对比损失应用于图形数据(Qiu 等人,2020 年;You 等人,2020 年;Zhu 等人,2020 年;Wan 等人,2021a;Wan 等人,2021b;Zhu 等人,2021 年),而不注意图像与图形之间的内在区别。对比损失被用来指导表征学习,将正对图像拉到一起,将负对图像推开。如图 1(a)和 1(b)所示,在 InfoNCE 和 NT-Xent 中,通过创建同一节点的不同增强视图,每个锚点都会形成一对正对。然后,InfoNCE 将来自不同视图的所有其他不同节点视为负节点。而 NTXent 则引入了更多的否定,将一个视图内和来自不同视图的所有不同节点都视为否定。值得注意的是,在 InfoNCE 和 NT-Xent 中,相邻节点都被视为负节点,然后被推离锚点。然而,在 GCL 中,与 CL 相结合的 GNN 通常基于同类假设,即相连节点通常属于同一类别(McPherson、Smith-Lovin 和 Cook,2001 年)。换句话说,连接的节点应该彼此相似,而不是相距甚远。由于图像和图形之间的内在区别,直接将 CV 中开发的对比损失应用于 GCL 会忽略网络拓扑结构,导致嵌入结果与 GNN 的同类假设相矛盾。
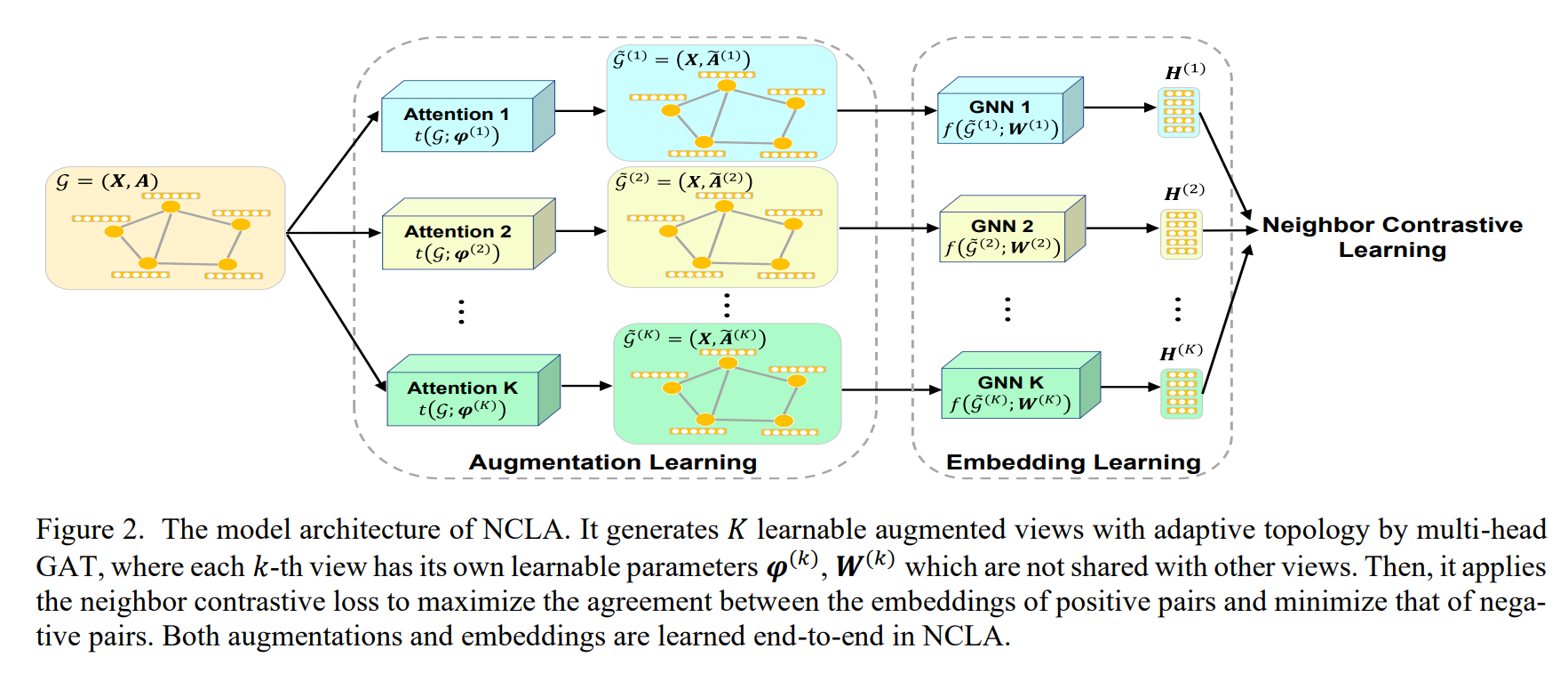
为了弥补上述局限,我们在这项工作中提出了一种新的 GCL 方法,命名为 NCLA,它将邻接对比学习应用于可学习图增强。一方面,NCLA 采用多头图注意网络(GAT)(Veličković 等人,2018 年)生成具有自适应拓扑的 K 个可学习图增强视图。这种可学习的增强可以自动兼容各种图数据集,而无需事先了解领域知识。此外,与可能严重破坏原始拓扑的不恰当手工图增强相比,NCLA 生成的基于注意力的可学习增强视图将保留与原始图完全相同的节点和边,但具有不同的自适应边权重。此外,现有的 GCL 方法对不同的增强视图使用完全相同的 GNN 编码器和绑定的可学习参数(You 等人,2020 年;Zhu 等人,2020 年;Zhu 等人,2021 年),而在 NCLA 中,每个增强视图都有自己的可学习参数。因此,NCLA 可以生成更安全的图增强,而无需对原始拓扑进行不当修改,同时还能保证不同增强视图之间的多样性。另一方面,与之前直接利用最初在 CV 中提出的对比损失(如 InfoNCE 或 NT-Xent)的 GCL 方法不同,我们为节点-节点 GCL 设计了一种新的邻居对比损失。所提出的邻居对比损失是对 NT-Xent 损失(Zhu 等人,2020 年)的新扩展,它将网络拓扑作为监督信号来定义 GCL 中的正负。具体地说,与 NT-Xent 中每个锚点只能形成一对正值不同,所提出的邻居对比损失允许每个锚点有多个正值。如图 1(c)所示,这些多个正对来自不同视图中的同一节点,以及锚点在同一视图中的邻居和来自不同视图的邻居。因此,视图内和不同视图中锚点的非邻居将被视为视图内和视图间的阴性。这项工作的贡献可总结如下:
- 与大多数现有的 GCL 方法必须根据数据集手动挑选手工图增强相比,所提出的 NCLA 首次采用了多头图注意力机制作为可学习的图增强函数,其中每个头对应一个增强视图。这种基于注意力的可学习图增强避免了对原始拓扑结构的不当修改,并能自动兼容各种图数据集。
- 现有的 GCL 方法直接将 CV 中的对比损失应用于图形数据,忽略了网络拓扑结构。CV 中的损失来处理图数据,而忽略了网络拓扑结构。据我们所知,我们的工作是 在节点-节点 GCL 中研究邻接对比学习的开创性尝试之一。通过将网络拓扑结构作为监督信号,允许每个锚点出现多个阳性结果。
- 在标准的 GCL 范式中,图增强和嵌入学习分两个阶段进行,可能需要进行双层优化。相比之下,在 NCLA 中,图形增强与嵌入学习是端到端的,因此具有很高的灵活性和易用性。
- 在各种图数据集上进行的大量实验表明,NCLA 在使用稀缺标签进行半监督节点分类时,始终优于最先进的 GCL 方法,甚至优于某些监督 GNN。
方法